Introduction to Load-balancing with Nginx
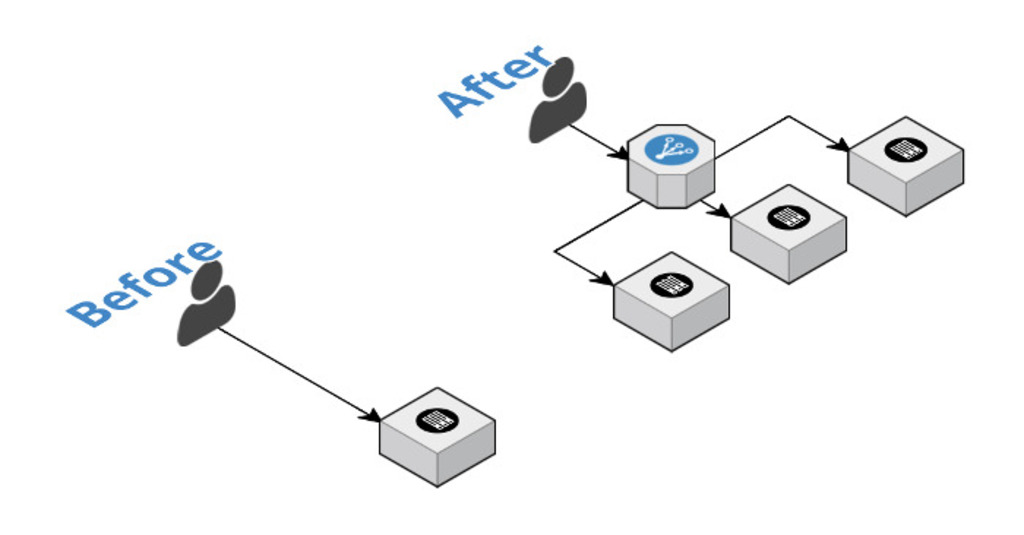
In the early stages of your application, one machine might be enough to handle the requests for your application. But as you scale, you may need multiple machines or instances to handle the load. How do you direct requests to multiple machines? That’s where a load balancer comxes in. Instead of requests coming directly to your one instance, they will come to your load balancer, which will take the responsibility to distributing those requests across your instances.
We’ll set up an experiment later to demonstrate load balancing with Nginx. The plan is to use Vagrant and its multi-machine configuration to set up 3 machines, 1 master and 2 slaves. We’ll send requests to the master and watch Nginx load balance them to the slaves.
Before we do that, let’s explore load balancing in Nginx a little bit more.
Load Balancing with Nginx
Load Balancing Methods
Let’s say the first request comes to your load balancer, and it sends the request to your first application server. The server processes the request, generates the response, and sends it back to the load balancer, which then sends that response back to the user. What happens with the next request? The load balancer will send it to the second application server, and the same process happens. This is load balancing 101. The technique in use here is called round-robin, where the load balancer distributes the requests to each application server under it in sequence. If you don’t specify a method, this one is the default. The configuration in Nginx for this would look like this:
upstream my_app {
server server1.example.com;
server server2.example.com;
server server3.example.com;
}
In the above configuration, the requests for my_app are being distributed to 3 servers.
Then there is a method called least-connected, specified by the least_conn; directive. This method will distribute requests based on the number of active connections on each application server, and Nginx will try not to overload an already busy server, sending the request to a less busy server instead. The configuration in Nginx would look like this:
upstream my_app {
least_conn;
server server1.example.com;
server server2.example.com;
server server3.example.com;
}
A third method is called IP hash, specified by the ip_hash; directive. In this method, Nginx will distribute requests based on the hash of the client IP address. What this means is that subsequent requests from the same client will go to the same application server, unlike in round-robin or least-connected. This allows session ‘stickiness’ or ‘persistence’, and can be useful if your application is not stateless. A significant downside here is that there is no automatic failover. If the server becomes unavailable, its per-session information also becomes inaccessible, and any sessions depending on it are lost. The configuration in Nginx would look like this:
upstream my_app {
ip_hash;
server server1.example.com;
server server2.example.com;
server server3.example.com;
}
Weighted Load Balancing
In the above described methods, all the servers are considered equal. But what if they’re not? What if you want a larger portion of requests to go to a select number of servers? That’s where weighting comes in. Consider the following configuration:
upstream my_app {
server server1.example.com weight=3;
server server2.example.com weight=2;
server server3.example.com weight=1;
}
The default weight is 1. The above configuration means that the first application server will get 3 times as many requests as server3, and the second will get twice as many requests as server3.
Handling Failure
Nginx will continue sending data to an application server even if it is not responding. This can be prevented by health checks. If the response from a server fails with an error, then Nginx can mark the server as inactive, and will not send requests to it until it is healthy again. These health checks are controlled by two directives: fail_timeout and max_fails. max_fails is the number of consecutive failed requests that should occur during fail_timeout for the server to be considered inactive. Once a server is inactive, Nginx will periodically probe the server to check whether it’s fine again and can serve requests or not.
The Experiment
Setting It Up
Let’s use what we’ve discussed above to set up a sample application.
We’re going to have 3 servers, 1 master and 2 slaves. We’ll send periodic requests to the master (using cron) which will send the requests to the slaves that we configure. If the experiment works, then the requests we send should be distributed evenly among the slaves (since we’ll be using the default round-robin method). We’ll make two changes to the master. One in the /etc/nginx/nginx.conf in the http section…
upstream test_app {
server 192.168.10.3;
server 192.168.10.4;
}
… and another in the /etc/nginx/sites-available/default file…
server {
listen 80 default_server;
listen [::]:80 default_server ipv6only=on;
location / {
proxy_pass http://test_app;
}
}
I’ve created a Vagrantfile so we can bring up all 3 servers at once, with all the configuration in place:
Vagrant.configure('2') do |config|
config.vm.define 'master' do |master|
master.vm.hostname = 'mm-master'
master.vm.box = 'ubuntu/trusty64'
master.vm.network 'private_network', ip: '192.168.10.2'
$script = <<SCRIPT
apt-get update;
apt-get -y install nginx
echo "server { listen 80 default_server; listen [::]:80 default_server ipv6only=on; location / { proxy_pass http://test_app; } }" > /etc/nginx/sites-available/default
sed -i 's/http {/http { upstream test_app { server 192.168.10.3; server 192.168.10.4; }/g' /etc/nginx/nginx.conf
service nginx restart
SCRIPT
master.vm.provision "shell", inline: $script
end
config.vm.define 'slave_1' do |slave_1|
slave_1.vm.hostname = 'mm-slave-1'
slave_1.vm.box = 'ubuntu/trusty64'
slave_1.vm.network 'private_network', ip: '192.168.10.3'
slave_1.vm.provision 'shell',
inline:'apt-get update; apt-get -y install nginx'
end
config.vm.define 'slave_2' do |slave_2|
slave_2.vm.hostname = 'mm-slave-2'
slave_2.vm.box = 'ubuntu/trusty64'
slave_2.vm.network 'private_network', ip: '192.168.10.4'
slave_2.vm.provision 'shell',
inline:'apt-get update; apt-get -y install nginx'
end
end
Just do vagrant up and all 3 machines will come up at once. Thank you Vagrant :)
Testing It Out
Now we need to send requests to the master. What we need to do is send the current minute with every request so that we can see which request was sent to which slave. Just add the following cron to your system…
* * * * * curl http://192.168.10.2/index.html?`date +"%M"`
… and wait for an hour.
This is a portion of the access log for the master. Note the numbers after index.html?.
192.168.10.1 - - [27/Aug/2016:17:31:00 +0000] "GET /index.html?01 HTTP/1.1" 200 612 "-" "curl/7.43.0"
192.168.10.1 - - [27/Aug/2016:17:32:00 +0000] "GET /index.html?02 HTTP/1.1" 200 612 "-" "curl/7.43.0"
192.168.10.1 - - [27/Aug/2016:17:33:00 +0000] "GET /index.html?03 HTTP/1.1" 200 612 "-" "curl/7.43.0"
192.168.10.1 - - [27/Aug/2016:17:34:01 +0000] "GET /index.html?04 HTTP/1.1" 200 612 "-" "curl/7.43.0"
192.168.10.1 - - [27/Aug/2016:17:35:01 +0000] "GET /index.html?05 HTTP/1.1" 200 612 "-" "curl/7.43.0"
192.168.10.1 - - [27/Aug/2016:17:36:00 +0000] "GET /index.html?06 HTTP/1.1" 200 612 "-" "curl/7.43.0"
192.168.10.1 - - [27/Aug/2016:17:37:00 +0000] "GET /index.html?07 HTTP/1.1" 200 612 "-" "curl/7.43.0"
192.168.10.1 - - [27/Aug/2016:17:38:00 +0000] "GET /index.html?08 HTTP/1.1" 200 612 "-" "curl/7.43.0"
192.168.10.1 - - [27/Aug/2016:17:39:00 +0000] "GET /index.html?09 HTTP/1.1" 200 612 "-" "curl/7.43.0"
192.168.10.1 - - [27/Aug/2016:17:40:00 +0000] "GET /index.html?10 HTTP/1.1" 200 612 "-" "curl/7.43.0"
This is the access log for slave_1.
192.168.10.2 - - [27/Aug/2016:17:31:00 +0000] "GET /index.html?01 HTTP/1.0" 200 612 "-" "curl/7.43.0"
192.168.10.2 - - [27/Aug/2016:17:33:00 +0000] "GET /index.html?03 HTTP/1.0" 200 612 "-" "curl/7.43.0"
192.168.10.2 - - [27/Aug/2016:17:35:01 +0000] "GET /index.html?05 HTTP/1.0" 200 612 "-" "curl/7.43.0"
192.168.10.2 - - [27/Aug/2016:17:37:00 +0000] "GET /index.html?07 HTTP/1.0" 200 612 "-" "curl/7.43.0"
192.168.10.2 - - [27/Aug/2016:17:39:00 +0000] "GET /index.html?09 HTTP/1.0" 200 612 "-" "curl/7.43.0"
And this is the access log for slave_2.
192.168.10.2 - - [27/Aug/2016:17:32:00 +0000] "GET /index.html?02 HTTP/1.0" 200 612 "-" "curl/7.43.0"
192.168.10.2 - - [27/Aug/2016:17:34:01 +0000] "GET /index.html?04 HTTP/1.0" 200 612 "-" "curl/7.43.0"
192.168.10.2 - - [27/Aug/2016:17:36:00 +0000] "GET /index.html?06 HTTP/1.0" 200 612 "-" "curl/7.43.0"
192.168.10.2 - - [27/Aug/2016:17:38:00 +0000] "GET /index.html?08 HTTP/1.0" 200 612 "-" "curl/7.43.0"
192.168.10.2 - - [27/Aug/2016:17:40:00 +0000] "GET /index.html?10 HTTP/1.0" 200 612 "-" "curl/7.43.0"
As you can clearly see, the requests were evenly distributed. One slave received all odd requests, the other all even requests. This is because of the round-robin method.
And that’s basic load balancing with Nginx.
What’s Next?
Try the above experiment with ip_hash. Just add ip_hash; to nginx.conf and restart the server. You should see all requests going to one server now, because the distribution is based on a hash of the client IP address.

Help me fuel up so I can keep typing typing typing...
&emoji=☕&slug=ayushsharma&button_colour=FFDD00&font_colour=000000&font_family=Cookie&outline_colour=000000&coffee_colour=ffffff)
